PDF types in PDFtalk
A PDF consists of a network of objects which are connected through their attributes. The PDF specifiction defines restrictions for what objects can be held by an attribute.
The restrictions specify
- which type of object including forms like
Array of aTypeorDictionary of aType. - whether it is or can be indirectly held by a reference
- whether it is required or optional.
These restrictions are called Attribute types in the following.
Attribute types
An attribute is represented as method of a PDF object. The methods are categorized in the protocol accessing entries. The methods name should be as close to the name in the specification. They usually start with a capital letter (unlike normal Smalltalk methods). The attribute type is defined by pragmas (method tags) in the method. The code of the method returns the object stored in or referenced by the attribute, or a default if the attribute is not required.
The following pragmas are used for declaring a type:
- #type: *aSymbol* The value (or referenced value) should be of type aSymbol
Catalog>>PageMode <type: #Name>
- #typeDirect: *aSymbol* The value should be of type aSymbol
Trailer>>Size <typeDirect: #Integer>
- #typeIndirect: *aSymbol* The value should be a reference to an object of type aSymbol
Trailer>>Root <typeIndirect: #Catalog>
- #typeArrayOf: *aSymbol* The value should be an array with values (or referenced values) of type aSymbol
Pages>>Kids <typeArrayOf: #PageTree>
- #typeDictionaryOf: *aSymbol* The value should be a dictionary with values (or referenced values) of type aSymbol
Resources>>ColorSpace <typeDictionaryOf: #ColourSpace>
An attribute can contain a number of alternative type declarations of which only one should apply. The scope of the alternative types should not overlap.
Page>>Contents <type: #Contents> <typeArrayOf: #Contents>
The symbol in the declarations above is the PDF type name of the object.
PDF Object types
The type hierarchy of PDF objects is shallow and oriented by the use of types in attributes, not by class membership. For example, there are no subtypes of Dictionary or Stream.
Implementation
When PDF objects are read from a file, the are syntactically differentiated as primitive object (Number, String, Name, Boolean etc.) or as Array, Dictionary or Stream. These are raw unspecified objects.
When such an object is assigned to an attribute of a Dictionary or Array with at:put:, the types are checked and the raw object is specialized to a fitting subclass. The process can be explained best with a sequence diagram:
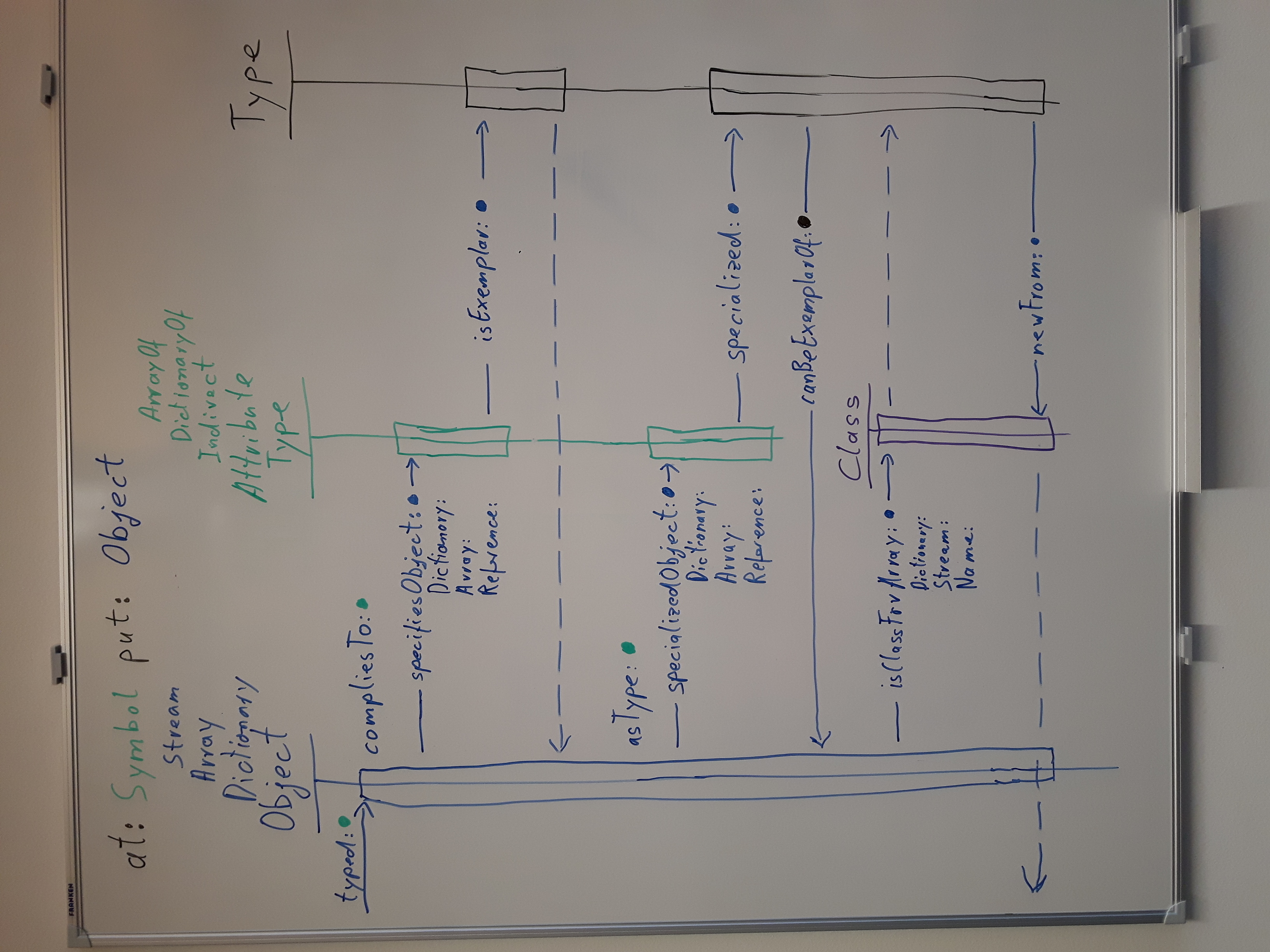
(the picture has the wrong orientation…)
(proper description to come…)